ReSharper EAP build 222
totally barfed on one of my source files and I was too lazy to reinstall build
219. The result? I was working on this one file for a couple of hours without
any help from R# (no advanced syntax highlighting, static analysis, improved
intellisense etc.)
I would like to reassert my statement that R# is the best thing that happened
to C# programmers since, well, C#. Working with Visual Studio 2003 and without
R# feels a little like trying to use a pen with an amputated
finger.
Chris has finally released a beta
version of PostXING v2.0 (an opensource
blog client for Windows)! The development version is pretty stable and usable,
but the more people that use it and post
bugs and feature requests the more motivated the developers get 
Grab it from Project
Distributor (requires .NET
2.0).
I've been working with build 219 for about a week now. With Visual Studio 2003 it's perfectly stable (only one exception so far), seems considerably faster and I haven't encountered any major (and very few minor) bugs so far. I haven't worked with Visual Studio 2005 at all over the last week (sorry Chris... project schedules ) so I've nothing to report on that front. I'll keep the ReSharper: New And Improved post up-to-date, as always.
While working on one of our projects at Monfort, we encountered a very
strange problem. The project was dependant on several COM objects, one of which
queries a database according to a predefined interface and returns the results
in an ADO Recordset. Our project is key-signed, so
we had to import the COM objects using the .NET SDK tlbimp utility; everything worked perfectly until we added
the querying logic that receives the Recordset
result object. The class loader would throw an exception on calling the relevant
method (it was invoked dynamically) claiming that the "referenced assembly adodb.dll could not be found." To quote Monty Python: this is, of course, pure
bullshit. The imported ADODB wrapper was right there in the directory. I
couldn't figure out the problem in a reasonably timespan, and finally decided to
ignore it altogether by using the ADODB primary interop assembly distributed
with .NET 1.1. I added a reference to the ADODB PIA and everything compiled and
seem to run fine.
This turns out to have been a mistake. I was absent from work for a few days
getting ready for a test, and came back to find that a colleague has encountered
the same problem but elsewhere; examination of the compiled executable's
references (via ILDASM) revealed that it was in fact
generated with two separate references to ADODB with two different public
key tokens. One of the references was the PIA, which was just peachy, but
the other one (in the hidden namespace ADODB_19 of
all things) referenced a non-existing assembly with the same public key
token we sign our other assemblies with. I concluded that there must be
some sort of problem with the build process - left over dependencies that
weren't compiled properly or something of the sort. Cleaning up the build
directory and rebuilding did not alleviate the issue. In desperation I tried to
manually edit the project files but couldn't find anything.
I then decided that one of the COM object wrappers we created using tlbimp was, for some reason, referencing a non-existing
version of the ADODB wrapper; I went through the wrapper assemblies one by one
and managed to find the offending library. Turns out that tlbimp does not, by default, look for primary interop
assemblies and opts to import ADODB every single time (singing the new wrapper
assembly accordingly). When I deleted what I thought was a redundant ADODB
wrapper assembly, I in fact deleted a version of the wrapper that was referenced
by one the imported COM wrappers. So now all I had to do was add a /reference: directive to the tlbimp call in our build script and voilla - everything
works!
Only it doesn't. Another COM object which references ADODB was still
generated with the mangled assembly reference (i.e. it still referenced the
wrapper with our own public key). I retried all sorts of tricks and couldn't
figure out why it was generated that way; I eventually tried to re-import it
manually with a /strictref directive, which resulted
in the following error message:
C:\Temp>tlbimp SomeComServer.exe
/keyfile:PublicKey.snk /reference:"%PROGRAMFILES%\Microsoft.NET\Primary Interop
Assemblies\ADODB.dll" /strictref
Microsoft (R) .NET Framework Type Library to
Assembly Converter 1.1.4322.573
Copyright (C) Microsoft Corporation
1998-2002. All rights reserved.
TlbImp error: System.ApplicationException
- Type library 'ADODB' is not in the list of references
A fit of confused rage and an hour later I sat at the computer again to try
to figure things out; finally (as usual) it was just a matter of asking Google
the right
question:
The problem was that MyCOMLib.dll was compiled against ADO 2.5 and
the PIA released by MS is registered only for ADO 2.7. I don't have access to
the COM component to recompile it for ADO 2.7, so I had to get a PIA for ADO
2.5.
Further research into this turned out a little
detail most .NET developers are probably unaware of:
Issue 7: You experience problems working with components that
expect ADO 2.8 interfaces
The ADODB PIA that is included with Visual Studio 2005 is the same
component that was included with Visual Studio .NET 2003 and was built by
using the Microsoft .NET Framework 1.1. The ADODB PIA was built to interact
with ADO 2.7 interfaces and has not been updated to work with ADO 2.8
interfaces.
Therefore, attempts to use the ADODB PIA together with components that
expose ADO 2.8 interfaces will fail. This
scenario is not supported with the ADODB PIA.
Oh, great job, Microsoft! You spent so much time on the interop issues with
.NET (of which, by the way, there is an impressively small number), came up with
the concepts for Primary Interop Assemblies, Publisher Policy Files and
everything else that went into .NET in order to prevent DLL hell, you tout
Primary Interop Assemblies as a way for component publishers to guarantee that
their components are usable under .NET, and finally you go on to release a PIA
for one of the most widely used COM objects in Windows which only
supports one version!
So there you are, I hope this might save someone the frustration of having to
figure all of this out on their own.
As a footnote, ILDASM is one of the worst tools
I've ever used. I can't believe how Microsoft managed to wrap a useful debugging
tool with one of the most frustrating and least usable UIs I've ever
encountered. Don't know what I'm talking about? Try double-clicking on a node
(method, manifest, whatever). You can't run a search through the text; worse
still, you can't even Ctrl+A, Ctrl+C then paste into notepad! Only now, days
after I needed it, did it occur to me to rightclick and "select all". I suppose
it's OK if you don't follow the classic usability patterns and guidelines in a
small and esoteric development tool, but please try and exercise a bit of
common sense...
I couldn't access the comments on my own website for an indeterminate amount of time (at least a week) and had to dig in the sourcecode to find the culprit (now described in bug 1439112). To make a long story short, it appears I got my dasBlog cookies mangled, so if you have the same issue either contact me or get rid of all cookies from www.tomergabel.com. (If you're using Firefox and don't know how to access your cookies, here's how. If you use IE just go to d:/Documents and Settings/ username/Cookies).
Well not as such, no, but it sometimes feels like way. Particularly today,
when I wasted about 40 minutes on a bug that should've taken me less than 1
minute to work out, simply because of issues with the Visual Studio debugger
(2003, mind you - you'd think after three years it would be a mature
product?)
Check this out, for example:
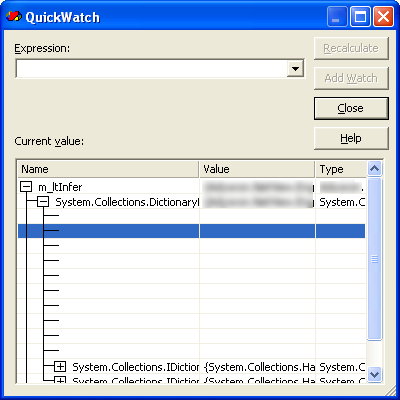
m_ltInfer is of a class deriving from DictionaryBase. What the hell am I
supposed to understand from this? The fact that I can't see my dictionary is bad
enough, but what's up with those blank spaces? And if that wasn't bad enough,
the immediate window's expression parser - limited to begin with - is flatly
lying to my face:

op.Parameters is an array. It has a Length property. The
intellisense displays it. The managed expression parser prints it out as the
default property for arrays. But attempting to access any of the object's
properties, or even its ToString() method, results in a "... does not exist"
error message. What the hell is going on here?
So I'm sitting at work, listening as I usually do to all sorts of music in
the background. I found myself listening to the excellent soundtrack written for
A Clockwork
Orange (which also happens to be one of the best movies I've ever
seen). Some of the classical pieces there have a distinct ring to them,
as if they've been performed in a very peculiar and distinct (somewhat
synth-y, for lack of a better word) style. It kept bugging me that I've
heard this someplace before, and after some 40 minutes it finally struck me: it
sounds highly similar to the soundtrack written for the movie Tron (also highly
recommended).
I took a better look at the tracks to see who wrote them - a Walter Carlos.
This was even more surprising for me, because I recall the Tron soundtrack
credited to a Wendy Carlos. What's up?
Some digging in
wikipedia proved once again extremely fruitful:
Her first six recordings were released under the name Walter Carlos,
although, being a transsexual woman, she had already changed her name from
Walter to Wendy. In 1972, Carlos underwent gender reassignment therapy. The
last release to be credited to Walter Carlos was By Request (1975). The first
release as Wendy was Switched-On Brandenburgs (1979). Carlos's first public
appearance after her gender transition was in an interview in the May 1979
issue of Playboy magazine, a decision she would come to regret as it brought
unwelcome publicity to her personal life. On her official site, her transition is
discussed in an essay stating that she values her privacy on the
subject.
The universe never ceases to surprise me.
I eventually get fed up with the various ReSharper builds I've been
using for the past 7 months; the stability has been going steadily downhill
since build 208 and performance is yet to improve. 217 originally seemed stable
but turned out to be useless both for VS2003 and VS2005. I've been waiting in
vain for a build as stable as 208 (which was practically beta-ready) but to
no avail.
Eventually I broke down and installed the official 1.5.1 (build 164) for
VS2003; unfortunately there are no official builds for VS2005 as of yet. I must
say working with the official version is a pleasure - it's absolutely stable
and, even more important, fast. So fast, in fact, that it feels just as
responsive as the "regular" VS2003 IDE is, and the only drawback is a small
increase in startup time.
I'm tenacious so I'll probably check the beta builds again when 218 is out,
but in the meantime I can't help but feel pleasure in working with a mature
product.
I came back to my apartment today after not being there for a couple of days,
to find that our (my flatmate and I) router died due to a power outage. I
needed internet access so I hooked up my laptop directly to the cable modem (a
Motorolla) and for some reason couldn't get a ping anywhere; some digging showed
me that for some reason the modem, which acts as a DHCP server, gives me a local
(192.168.x.x) IP address, no DNS servers and no default gateway.
The modem would return pings and the operational web interface showed
everything to be fine and dandy, so I spent the next 15 minutes having the most
futile conversation I've ever had with a tech support guy. Now as a programmer
and reasonably hardware- and network-savvy individual I figured that if a modem
and computer restart won't solve the issue it must have something to do with the
cable/ISP networks; there was nothing to indicate local failure, so I didn't
think to examine the obvious.
The Motorolla modem has a standby button.
I'll be damned if I know why, but it does. And someone pressed it. All it
took to get my internet connectivity back is to press it again. Which brings me
to the point: it is well known that one of the cardinal sins is vanity, it is
equally well known that programmers generally exhibit the three cadinal sins
(vanity, hubris and laziness, I think?). So if you're a programmer, whenever you
talk to tech support don't be a smartass. You'll save yourself time in
the long run.
Back when I used to code demos with friends as a pastime (1995 or so) we
would slave away on three or four PCs, at best interconnected with null-modem or
parallel (a.k.a laplink) cables; whenever someone would have a breakthrough we'd
reconnect the machines and shift sources around (sometimes opting to use
modems or floppies instead). Eventually we'd get to a more or less complete set
of codebases and integrate them into a single production.
That process could best be described as hectic. I'm amazed
we ever managed to get any work done, particularly in the absence of automatic
merge tools such as Araxis
Merge; the number of times we would accidentally overwrite or
modify each other's code, accidentally delete an object file or some other
stupid mistake was astounding. With that baseline in mind, when I was introduced
to SourceSafe back when I was serving in the Israeli army I was appalled. The
concept of a singular repository for sources (with write access to everyone on
the team, no less) seemed incredibly stupid, although in retrospect I couldn't
tell you why. SourceSafe's (severe) problems aside, I'd expect the fundamental
concepts of source control to strike a chord with me immediately, but it took a
while for that to happen; over the years I've developed pretty rigid standards
of working with source control - what should or should not be checked in, how
long is it OK to check out a shared file exclusively (more or less the only
option with SourceSafe...) and how to organize the repository effectively.
Fast forward to 2006. I'm working on a project that has several seperate
components; the project, which is actually version 2.0 of a certain
product, is kept in a central source control repository along with its
dependencies (libraries, documents, installables) and everything seems to be
fine. Only it isn't. The first problem is that the project was originally
developed for an external company which uses Perforce as its source control provider of
choice. We then brought the codebase back to Monfort and set out to rework the existing
components and develop new ones. This means that while large portions of the
code were being worked on, others remained completely untouched - in other
words, some projects were imported into our source control system (Vault) and others were
not. This proved to be very annoying when I had to re-integrate and test
some version 1.0 code today; it's worth noting that Visual Studio is anything
but graceful when it comes to handling unavailable providers or incomplete
bindings:
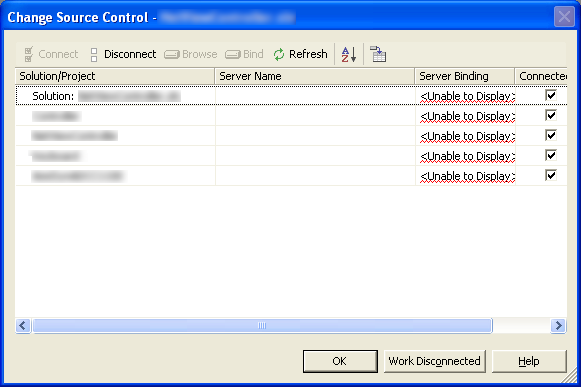 So
much for verbosity, but at least I can Work Disconnected...

...
right after I click on OK again.
That was only the first hurdle. The second was an apparent lack of attention
on a certain developer's part (sigh), who forgot to add installations for
certain 3rd party dependencies to the repository. Fast forward another fourty
minutes or so (DevExpress's installers
suck) and I was finally on my way to a working test build.
At that point, a new developer on the project approached me with some
compilation issues. This was pretty rudimentary stuff - installing a
public/private key container, path variables, 3rd party installations etc.,
but the guy couldn't be expected to know how to do any of this
stuff, let alone what needs to be done or where to get the
required files. Which brings me to the conclusion of this here rant:
- When you import a project into your development environment (source
control, build system, back up, etc.) take the time to get (re-)acquainted
with the codebase and make any necessary conversions. It'll pay off in the
long run,
- Always keep all dependencies safely tucked away in your source
control repository. That's as close to a file server as you are going to get,
it's properly backed up (isn't it?) and the files are kept close to
their target audience - developers on that particular project.
- A "Developer Workstation Setup" document is an absolute must-have.
Saves everyone a lot of time and headache.
- Try and maintain behavioural consistency between developers on a given
project. This doesn't have to (and preferably won't) extend to indentation and
code formatting issues, but some sort of check-in, documentation and
dependency resolution policy is important, if not for the project than at
least for your medical bill.
|