Back when I used to code demos with friends as a pastime (1995 or so) we
would slave away on three or four PCs, at best interconnected with null-modem or
parallel (a.k.a laplink) cables; whenever someone would have a breakthrough we'd
reconnect the machines and shift sources around (sometimes opting to use
modems or floppies instead). Eventually we'd get to a more or less complete set
of codebases and integrate them into a single production.
That process could best be described as hectic. I'm amazed
we ever managed to get any work done, particularly in the absence of automatic
merge tools such as Araxis
Merge; the number of times we would accidentally overwrite or
modify each other's code, accidentally delete an object file or some other
stupid mistake was astounding. With that baseline in mind, when I was introduced
to SourceSafe back when I was serving in the Israeli army I was appalled. The
concept of a singular repository for sources (with write access to everyone on
the team, no less) seemed incredibly stupid, although in retrospect I couldn't
tell you why. SourceSafe's (severe) problems aside, I'd expect the fundamental
concepts of source control to strike a chord with me immediately, but it took a
while for that to happen; over the years I've developed pretty rigid standards
of working with source control - what should or should not be checked in, how
long is it OK to check out a shared file exclusively (more or less the only
option with SourceSafe...) and how to organize the repository effectively.
Fast forward to 2006. I'm working on a project that has several seperate
components; the project, which is actually version 2.0 of a certain
product, is kept in a central source control repository along with its
dependencies (libraries, documents, installables) and everything seems to be
fine. Only it isn't. The first problem is that the project was originally
developed for an external company which uses Perforce as its source control provider of
choice. We then brought the codebase back to Monfort and set out to rework the existing
components and develop new ones. This means that while large portions of the
code were being worked on, others remained completely untouched - in other
words, some projects were imported into our source control system (Vault) and others were
not. This proved to be very annoying when I had to re-integrate and test
some version 1.0 code today; it's worth noting that Visual Studio is anything
but graceful when it comes to handling unavailable providers or incomplete
bindings:
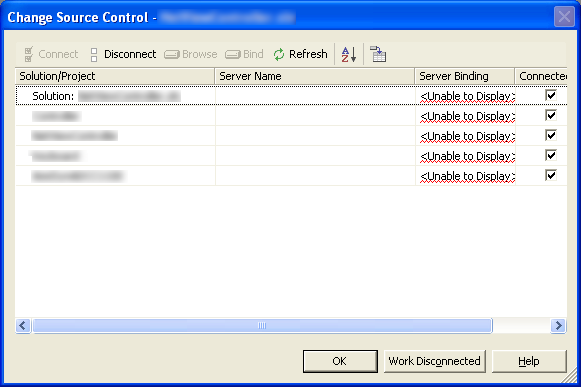 So
much for verbosity, but at least I can Work Disconnected...

...
right after I click on OK again.
That was only the first hurdle. The second was an apparent lack of attention
on a certain developer's part (sigh), who forgot to add installations for
certain 3rd party dependencies to the repository. Fast forward another fourty
minutes or so (DevExpress's installers
suck) and I was finally on my way to a working test build.
At that point, a new developer on the project approached me with some
compilation issues. This was pretty rudimentary stuff - installing a
public/private key container, path variables, 3rd party installations etc.,
but the guy couldn't be expected to know how to do any of this
stuff, let alone what needs to be done or where to get the
required files. Which brings me to the conclusion of this here rant:
- When you import a project into your development environment (source
control, build system, back up, etc.) take the time to get (re-)acquainted
with the codebase and make any necessary conversions. It'll pay off in the
long run,
- Always keep all dependencies safely tucked away in your source
control repository. That's as close to a file server as you are going to get,
it's properly backed up (isn't it?) and the files are kept close to
their target audience - developers on that particular project.
- A "Developer Workstation Setup" document is an absolute must-have.
Saves everyone a lot of time and headache.
- Try and maintain behavioural consistency between developers on a given
project. This doesn't have to (and preferably won't) extend to indentation and
code formatting issues, but some sort of check-in, documentation and
dependency resolution policy is important, if not for the project than at
least for your medical bill.
I'm a self-proclaimed part-time, low-budget audiophile (there's a
mouthful), so I often try to combine good performance with reasonable cost. To
that end, considering I spend about 80% of my time at work (and, up until
recently, home as well) with headphones on my head, the Sennheiser
HD600s I got about five years ago for the price of about 200 of today's US
dollars after shipping and taxes were the absolute best bargain I've
ever made. The Jean-Marie Reynaud Twin
MK2 speakers I also bought at about the same time were so impressive that
the lowest-priced comparable speakers were 60% more expensive.
Things have somewhat improved since then; the taxes on audio equipment in
Israel have been considerably reduced, although at some 34% they're still very
high (down from 70%...). I mentioned this before in my post regarding the Yakumo Hypersound Car. Since
then I went to an auto shop for some additional equipment, specifically a 6x9"
component set, 3.5" mids to replace the crappy ones in my Punto, a 12" Pioneer
sub and 2x60w (continuous) amp (I'll post the models number later - damned if I
remember).
  On
the left: Pioneer sub under the component speak, on the right: Yakumo Hypersound
Car installed While the CD receiver was a breeze to install, I'm pretty glad I didn't
attempt to do the rest of it alone; I don't know jack about car electronics and
some of the stuff involving the installation of the amp I didn't know to begin
with (such as hooking up the negative terminal to the car chassis) and I
would've done a heck of nasty job if I tried running some of the wires on my
own. On the other hand, contrary to my usual cautious self I didn't do much
market research and ended up paying considerably more than the equipment
was worth. It was definitely a learning experience, though, and I won't make
these mistakes next time.
That said, the sound is great - not perfect but I'm still tweaking it. The
Yakumo unit turns out to have very poor amplification; at first I thought the
specified 65dB signal-to-noise
ratio was a mistype in the product manual, but it turns out rather accurate;
there is a very audible hiss at even moderate volume levels (which I couldn't
hear earlier because of the crappy speakers I bought the car with) and the
rear-speaker sound is bright to the point of being harsh. This may or may not be
attributed to the Pioneer component speakers - if so you can bet that they'll be
replaced - but in the meanwhile I've found the amplification so horrid that I'm
replacing the 2-channel monobridged Pioneer amp with a quad-channel amp to drive
both sub and rear speakers (5- and 6-channel amplifiers are prohibitively
expensive, so I'll skip those for now).
The Yakumo unit also suffers from some pretty severe usability issues; the
TOC indexing times for USB devices (tested with a fully loaded iRiver
H320) were nothing short of abhorring (about 3 minutes from iRiver boot).
With CDs the problem is less of an issue, about 20 seconds for a 700MB CD, but I
still think it's rather stupid that the unit can boot up to the exact location I
last powered it off in but has to index the TOC first. The random mode is
extremely useful with compressed files, but why does it change track when I turn
it on? The fact that I can't navigate by folder (particularly with the existence
of a jog dial!) without going through the tedious search function is
ridiculous, and I've actually managed to get the unit's firmware to crash once
or twice (Update: actually, the unit seems to be extremely crash-prone). I believe most if not all of these problems can be solved with a
little work on the drive's firmware, but there is none from Yakumo. In my
opinion the solution would be to simply open-source the firmware; it's
probably based mostly on LGPL'd code to begin with,
and it would allow community involvement in empowering the brand. I, for one,
would be delighted to tweak the source code to my heart's content; it would make
the unit all that more useful. With the lackluster amplification and usability
issues it's very hard to recommend the unit to anyone but a die-hard OGG Vorbis fan. Update: Having owned this unit for several months I can safely say that it, quite plainly, sucks. It is crash-prone, error-prone, extremely slow on boot up, requires constant resets and provides very low sound quality to boot. Its one saving grace is Vorbis support, and even for me that's not enough to save it from a "piece of crap" verdict. I'm going to replace this thing as soon as I find a decent alternative; the XiphWiki points at a similar product from Silvercrest, but given the track record of these things I'm inclined to forego in-dash players altogether and go for a hard-drive based solution. Now if I can only find a decent one...
Whenever I get a new machine (at work, at home, anywhere) I'm always
astounded by the sheer amount of time it takes to get it up and running. I
don't mean just the basics, I mean a fully-functional platform that is set up
just the way I'm used to, right down to the folder display settings in Explorer
and the toolstrip I always like on the right side of the screen.
I mean, seriously, there's gotta be a better way to do this. The following
applications are just the basic things I need to be efficient:
- Windows XP Professional, drivers, settings
- Mozilla Firefox, extensions,
profile import
- Thunderbird, profile
import
- Maxthon
- Microsoft.NET 1.1 and 2.0
- Visual Studio 2003 and 2005
- ReSharper (one version
for each), import settings, resolve keyboard conflicts
- GhostDoc (one
version for each)
- Gaim, profile import
- FileZilla
- Latest JRE (java runtime environment)
- RssOwl, profile import
- Total Commander, plugins,
customization
- 7-zip
- Microsoft Office, OpenOffice.org (Hebrew version)
- SourceGear Vault client
- CDBurnerXP Pro
And that's just to get me through the day. It doesn't include all the
multimedia and development tidbits, like:
I reckon the net installation and customization time is over 10 hours
(some installations can be done in parallel, some can be deferred to a later
time). That is a lot of time to spend on just setting up your machine.
The problem with using Ghost or some similar software is that I get a system
without all of my current data (profiles, files, documents etc.), and as for
virtual machines, they're simply not fast enough yet for constant use (at least
on my modest home desktop or laptop).
... there's an online video of 8088 Corruption that is an absolute must-see.
Trixter, you rock!
1. Ever since I bought my car several months ago I've been looking for a
decent audio platform to put on it. My primary concern was support for the
excellent Vorbis audio codec - this is the
codec I use most often in my music archive due to its superiour quality (I spent
hours and hours comparing best-case rips encoded with LAME [MP3] and Vorbis and have found
Vorbis to be the better codec - I'll write another post about that if anyone's
interested), smaller footprint and patent-free nature.
Although Vorbis (and its container format OGG) has seen lackluster support
from hardware vendors since its introduction in 2001, the past two years have
seen thoroughly improved support for the codec -- most portable players
(including oblique Chinese models) now support Vorbis just fine. Cars, however,
are a completely different issue: there are exactly four car-oriented products
that support Vorbis (the Vorbis wiki contains a complete list)
and I wouldn't settle for 'just' an MP3 player. For a time I was considering
building an ITX-based car computer, orevaluated products such as the PhatBox;
eventually I settled on a more mundane in-dash CD receiver called Yakumo
Hypersound Car. The decision was mostly based on the cost of the more exotic
solutions and the much higher risk of someone trying to break into my car.
 The Yakumo is very difficult to get; you can either get it from
Amazon UK (but they don't deliver electronics overseas) or from certain
German vendors. I eventually ordered the unit from a very efficient
eBay shop and it finally arrived last week.
Anecdote: Israeli tax is murder; not only did I have to pay the
16% European VAT (having bought the unit from a German reseller), which I may or
may not be able to get back, and the €40 shipping fee; on top of that I had
to pay an additional 15% customs tax and 16.5%
Israeli VAT, and that's on the shipping too! So bottom line, a €96 unit cost me
close to €200, shipping included. That's an insane amount of money to pay just
for the privilege of buying something you can't get in your own country, and
even if you could you'd probably be forced to pay the local importer handsomely.
And imposing a tax on the shipping fee should be proper illegal.
Installation was a breeze (any experienced technician should be able to
do it in 20 minutes; I'm not an experienced technician so it took close to an
hour with my dad helping out), and with everything hooked up I inserted a
freshly-burned CD, held my breath and... woah! Iris playing in my car in gorgeous
Vorbis! That alone was worth the price of admission. I do have some qualms with
the device, though, primarily the lackluster display (yeah, OK, blue
backlighting has been out of fashion for at least a couple years) and the
awkward navigation (you can't easily navigate by album), but considering the
very reasonable initial cost of the unit, which also comes with an SD
card-reader, USB port for mass storage devices and remote control (!) and the
so-far excellent sound quality which easily rivals the generic JVC CD receiver I
had earlier, this product comes highly recommended. Update (after a short period of constant use): I do NOT recommend this product.
2. I just got my second Microsoft
Natural Ergonomic Keyboard 4000 (a.k.a Ergo 4000). It has replaced the
trusty Model M; we'll see if it lives up to the hype. I actually got one last
month, but returned it the same day because Hebrew character engraving looked as
though they were hand-drawn by a five year-old with severe ADD.
This one feels a bit different but is so far extremely comfortable; I'm
astounded that no other keyboard features a cushioned hand-rest like this
one, it makes working with the keyboard infinitely more comfortable to the point
where I don't know how I managed to live without it all these
years. I've used Microsoft Natural keyboards for the last ten years so the
ergonomic ("split") design is one I'm very familiar with. There are some
differences though - some keys are aligned a bit differently and require
different finger movements, but so far I seem to be getting used to the layout
very rapidly. The tactile feel of the keyboard is also different from the
Microsoft Natural Elite I've been using these past few years ('till I switched
to the Model M); it's softer and at first seems slightly less responsive (during
the first couple hours of working with the keyboard I was very prone to the
classic manglign-of-the-last-two-lettesr syndrome) but as soon as you adjust the
strength with which you depress the keys it becomes very natural (no pun
intended). Unlike my dad's crappy Microsoft Desktop Multimedia keyboard
this one has the f-lock enabled by default, and so far I haven't touched the
extra keys or zoom slider. At $65 it's not cheap but not prohibitively expensive
either (unlike the $80 Logitech
MX1000 mouse I use).
So far, so good. I'll post further comments on the keyboard when I've used it
for a while.
I was doing some research on how to use a certain component we were given as
part of a project. It is a COM object written with ATL; I referenced it via
interop and everything seemed to work perfectly. Until we integrated it
into the main codebase, that is. For some reason the same code would barf on any
call made to a method/property of a legacy ADO Recordset object; an instance of Recordset is passed by reference to the COM object,
which initializes it to certain values. For some reason any call to the Recordset instance after the COM method call would result
in a NullReferenceException being thrown by the
framework.
Oddly enough, tests on the research codebase (on my own machine) now proved
to generate the exact same error; considering I had written and tested the code
merely two days before, I was disinclined to believe the code to be at fault.
Something told me to look into the interop assemblies - we sign every
COM/ActiveX import in the project with our own keyfile using a script which runs
tlbimp/aximp - and reverting to the VS-generated interop
assemblies did indeed resolve the issue. I couldn't find any solution using
Google (a Groups search provided a similar
issue with no solution offered). Finally I stumbled upon the following quote
in this
article:
But
Primary Interop Assemblies have another important use. Interop Assemblies
often need modifications, such as the ones shown in Chapter 7 to be completely
usable in managed code. When you have a PIA with such customizations
registered on your computer, you can benefit from these customizations simply
by referencing the type library for the COM component you wish to use inside
Visual Studio .NET. For example, the PIA for Microsoft ActiveX Data Objects
(ADO), which ships with Visual Studio .NET, contains some customizations to
handle object lifetime issues. If you created your own Interop Assembly for
ADO using TLBIMP.EXE, you would not benefit from these
customizations.
Since the ADO COM object was automatically imported along with our
proprietary objects this got me wondering what sort of "custom optimizations" I
might be missing out on. A quick look in the knowledgebase article on the
ADO PIA
didn't prove very effective (short of a vague statement about "the ADO PIA helps
to avoid certain problems with ADO and .NET COM interoperability") but I decided
to try it out anyway; I removed the preexisting reference from the project,
added "adodb" from the .NET tab in the Add References dialogue (you
could look it up manually in the GAC, but why would you?), fired it up
- problem solved.
As an anecdote, referencing an external library with tlbimp's /reference
command line parameter (particularly the ADODB PIA from the GAC) did not stop it
from generating the imported library anyway. Just go ahead and
delete it.
I saw this joke and couldn't help myself. Sorry, it won't happen again.
Or rather, help me to help them  I keep filing bugreports (which are usually fixed by the next release) and feature requests, but in order to get attention the feature requests need votes. Have a look at these two feature requests and vote (or comment) if you think they're important. If not, tell me why:
Additionally, build 215 is out.
Or: How I Learned To Stop Worrying And Love Firefox
(this is a Dr.
Strangelove reference, in case that wasn't
obvious).
There are some fundamental principles of UI design
most developers have not taken to heart. Developing a
good UI is hard, designing one is excruciatingly
hard. A good UI designer needs to have a very
developed sense of how a typical user thinks; it is
therefore a commonly held belief that most
programmers make lousy UI designers because they
can't "stoop to the level of the non-technical user" (a slightly less rehearsed mantra is that developers are users as well and are susceptible to the same problems with crappy UI, although possibly a little more forgiving).
The developer-oriented UI trend is most obvious with open source software,
but it is actually exacerbated when we're talking
properietary, even if free, software. An open source
tool that is essentially really good but has crappy
UI will eventually attract someone who is actually
capable in that department. Take a look at Eclipse,
OpenOffice.org, The Gimp etc. - although based on a
more or less solid foundation, these tools were
practically useless a few years ago and have only
become mainstream when they made leaps and bounds in
usability. An even better example is Firefox;
although I was personally attracted to Firefox on
merit of its technical achievements, I was only able
to sell it to friends and relatives becaues it is
infinitely more usable than IE and just as free (I
mean come on, does anyone doubt why Opera never
gained marketshare?)
A proprietary program however, even if
fundamentally sound and useful, can only grow better
by the efforts of its owners. Even the most obvious
bugs can never be fixed by a 3rd party. w.bloggar is a
classic example of this; the last version was out in
January and, despite being fundamentally stable and
usable, has huge flaws which the author never fixed,
instead allowing the software to stagnate. I reckon a
lot of you, at this point, are thinking along the
lines of "hey, you get what you pay for; you
should be thankful that w.bloggar is free, let alone
supported!" In a way you are right, but also
dead wrong. As far as I know Marcelo (the author of
w.bloggar) isn't seeing much money from his work on the software; what money he does get is from donations.
So why not release the source? Donation systems seem
to work for high-profile open-source projects at
large, why not for w.bloggar? At least that way
someone can fix the bugs that
(for me) turned w.bloggar from a useful tool to a
constant cause of frustration.
To get to the point, I wrote a blog entry in
w.bloggar (specifically the one about missing tools), published it and went on with my
work. At the end of the day I left the machine
running (as I always do when I'm not leaving for days
at a time) along with w.bloggar. Why'd I leave
w.bloggar open, you ask? Simple: one of these glaring
bugs I mentioned is that w.bloggar does not retain my
preview template options (CSS links and so forth),
and it's a pain in the ass to enter them manually
whenever I want to edit or write a new post. Anyway,
w.bloggar has a "Clear Editor after Post"
option which in my case was disabled. This means that
whenever w.bloggar finishes uploading a post, it retains the
text and changes its internal state so that
subsequent clicks on Post update the same entry (as opposed to creating a new one). So what basically happened is that when I came in today and wanted to write the note on OpenOffice.org, the previous post was still "live" on w.bloggar. Usually at that point I click on New (which shows a nice, useless warning dialog) and get on with it; this time I guess I was distracted, just shift-deleted everything and proceeded to write. When I next clicked on Post and got the "Post so-and-so-GUID updated successfully" notice I knew I was up the creek: my earlier post was overwritten with no prior warning, no delay and worst of all: no backup.
Which brings me to my first point: w.bloggar sucks. Bugs (like not retaining options and the most defective HTML syntax highlighting known to man) aside, this is a huge usability problem - a user can (and evidently will) inadvertently erase his/her own work and have no way to recover it. The undo buffer is not even remotely deep enough; there are no dialogs to warn you that you're about to update a live post, and there are no backups-shadow copies-anything of published posts if you do not actively save them. Worst of all, there is no-one to mail, no bug tracker, not even a forum (the forum link on the w.bloggar site is broken). My first resolution for 2006: make more effort on PostXING and help Chris make it actually useful.
Now that that's out of the way, time for some damage control; w.bloggar is useless in recovering the lost content, dasBlog does not maintain any sort of backup (side resolution: implement shadow copies into dasBlog) and considering how cheap my hosting package is I seriously doubt my ISP would help me recover yesterday's daily backup (assuming there even is one) without significant trouble and/or cost. The only option that comes to mind is the browser cache; in case it isn't obvious from the title (and the large "take back the web" icon on the right), I use Firefox. Going over the cache files manually proved futile as most of them seemed to be binaries of some sort; some research showed me that you can access cache statistics by navigating to about:cache; from there you can access an actual dump of the in-memory and on-disk hashes. Looking at the on-disk cache via about:cache?device=disk and searching for something useful, I found a cache entry for the editing page. Clicking the link did not prove readily useful (the actual content is not displayed), but the information displayed shows two important details: the file location and the content encoding (in this case, gzip). This explains the strange binaries I found in the cache! A quick decompression via the excellent 7-zip and I had my content back. Second point of the day: Firefox has once again proved its mettle. Firefox rocks!
Coninciding with the release of OpenOffice.org 2.0.1, the OOo.il team has released a Hebrew version based off of the 2.0 codebase! It is sponsored (ironically) by the Israeli Ministry of Finance.
I haven't really tested this version but I do hope it's all it's cracked up to be. Time will tell.
|